Distributed Elixir (Erlang) Guide
Connecting Elixir nodes (a node can be either a Phoenix app or a simple Elixir mix project) together in a distribution is deceivingly simple: pass a name when you start the application and ping another node and you're set. But there are a lot of moving parts in order to support that. In this post I will try and dig deeper into how Distributed Erlang works with the goal of giving you enough knowledge to not only run a cluster efficiently but also be able to tune and debug it.
Why bother?
The first question we should always ask is "Do we need this?". I have worked with Elixir for over 6 years and I never had the need to connect Elixir nodes in a distribution. There are two reasons for that: for one, maybe my use cases did not call for distributed Elixir and two, more importantly, we used either a reliable database (Postgres) or a reliable key-value storage (Redis) to keep the Elixir apps stateless and not connected to each other.
Let's talk about use cases that strongly push us into distributing our nodes. The most recent one I heard about was from Chris McCord at ElixirConf US 2023 when he talked about LongPoll support in LiveView. First time the client connects to the server using LongPoll, Phoenix starts a process to keep track of state in between state-less HTTP requests (this is the case for both LiveView diffs or a regular Phoenix Channel). Now if that request hits another node in a load balanced setup, normally there would not be a process or a way to route to that process from a different node. But thanks to how message passing works in Erlang, the second node can seamlessly call the process on the original node the same way it would call a local process.
The second example is a large scale chat app like Whatsapp that supports billions of connected clients. Just to go back to my original statement about never having to connect nodes in over 6 years, even for a chat app you can get away with stateless Elixir nodes: one can use Redis PubSub to handle the distributed subscriptions (there's even little effort you would need to do for that because Phoenix.PubSub comes with a Redis adapter). But the moment you need to think about clustering your Redis servers because you've outgrown one instance, well, that's when it's worth looking at alternatives like your good old Erlang distribution: now you're dealing with similar tradeoffs in distributed state. But let's get back to Whatsapps example. This is just information I managed to gather from public talks the folks from Meta gave, but it seems like they use the distribution mainly for routing purposes. Mobile Whatsapp apps connect to Chat servers and when you need to message another user, their system will route the message until the right Chat server is found and the message is delivered to a process mailbox on the right server.
If you think about it, both examples roughly fall into the "routing" pattern more so than the "distributed state" pattern. And that's good, because distributed state is not easy to deal with.
Starting from scratch
You have probably seen a lot of examples of how you connect nodes together by passing the right VM arguments to the Erlang runtime. In order to learn more about this I will show you how to manually start the distribution and look at all the processes and daemons involved along the way.
First let's make sure that this daemon called epmd is not running. I'll explain later why we are doing this:
$ sudo killall epmdNow we can start our console:
$ iex
iex(1)> Node.self()
:nonode@nohostAs you can see, the node assumes a nonode@nohost identity because we have not specified a --name or --sname when we started iex. Let's try and start the distribution:
iex(1)> :net_kernel.start(:app, %{ name_domain: :longnames })
11:19:57.722 [notice] Protocol 'inet_tcp': register/listen error: econnrefused
{:error,
{{:shutdown, {:failed_to_start_child, :net_kernel, {:EXIT, :nodistribution}}},
{:child, :undefined, :net_sup_dynamic,
{:erl_distribution, :start_link,
[
%{
clean_halt: false,
name: :app3,
name_domain: :longnames,
supervisor: :net_sup_dynamic
}
]}, :permanent, false, 1000, :supervisor, [:erl_distribution]}}}EPMD
The reason we get this error is because the epmd daemon is not running (if you followed along and killed it earlier). Epmd stands for Erlang Port Mapper Daemon and is a separate program running outside of the Erlang Runtime System (ERTS). Chances are it runs on your system if you ever used RabbitMQ locally or ever started any node with a name. Erlang runtime will either start one or use an existing running epmd daemon.
EPMD keeps track of the node or nodes running in one machine. When a remote node tries to connect, it is epmd that provides the port information. The distribution (inet_tcp_dist) calls the EPMD module to get the IP address and port of the other node. If you're interested to dig deeper, the guide on how to implement an alternative discovery in Erlang is a great read.
Let's start it, but instead of making it a daemon, let's keep it attached and also in debug mode:
epmd -debugBack in the console, we can now start the distribution:
iex(1)> :net_kernel.start(:app, %{ name_domain: :longnames })
{:ok, #PID<0.109.0>}There are a few servers started here under the application's supervision tree, we'll look at all of them one by one, but first let's concentrate on epmd. If you check your terminal you can see the output after we started our distribution:
epmd: Sat Oct 14 11:40:42 2023: epmd running - daemon = 0 epmd: Sat Oct 14 11:40:54 2023: ** got ALIVE2_REQ epmd: Sat Oct 14 11:40:54 2023: registering 'app:1697298055', port 50785 epmd: Sat Oct 14 11:40:54 2023: type 77 proto 0 highvsn 6 lowvsn 5 epmd: Sat Oct 14 11:40:54 2023: ** sent ALIVE2_RESP for "app"
When a we start the distributed node, it sends an ALIVE2_REQ to the EPMD daemon. The daemon responds with ALIVE2_RESP back.
If you want to learn more about whatALIVE2_REQ,ALIVE2_RESPand all the other types of messages, you can check out the distribution protocol docs in Erlang
Erlang is asking epmd to assign a port to our newly started node called app. You can see that the daemon registers the app along with the epoch timestamp and port 50785.
Let's connect a second node now, in a separate terminal window. This time we start the distribution at boot time:
iex --name app2
And it looks like epmd picked that up as well:
epmd: Sat Oct 14 11:46:24 2023: ** got ALIVE2_REQ epmd: Sat Oct 14 11:46:24 2023: registering 'app2:1697298385', port 50826 epmd: Sat Oct 14 11:46:24 2023: type 77 proto 0 highvsn 6 lowvsn 5 epmd: Sat Oct 14 11:46:24 2023: ** sent ALIVE2_RESP for "app2"
You may be wondering where the port numbers are coming from. Notice that epmd just increments them for each local node we run. The ports are random high number ports that we can override with the following VM arguments. This is a good idea if you need to filter those ports in your firewall and need to know a range ahead of time:
iex --erl "-kernel inet_dist_listen_min 8001 -kernel inet_dist_listen_max 8100"
Connecting the nodes
Now that we have the distribution started on both nodes, let's connect them, run this from one of the consoles:
iex> Node.connect(:"app2@raz.local")
Isn't it great that we won't have to think about port numbers when connecting nodes together ? This is not just the case when we are connecting to a local node, going to a remote node works the same. This is because epmd connects to remote nodes on a known port (4369) and facilitates the port and IP mappingMake sure to use your own local domain. Now you can check in the other node that it lists the node it just connected to it. By default, the connections are transitive - meaning that nodes will connect not just to the node you direct them to, but to all the other nodes each node they connect to is connected with.
iex(app2@raz.local)1> Node.list() [:"app@raz.local"]
It might help to visualize the processes that are started at this point. This supervision tree is started as part of app and app2 application supervision tree. I didn't include everything else to keep things simple.
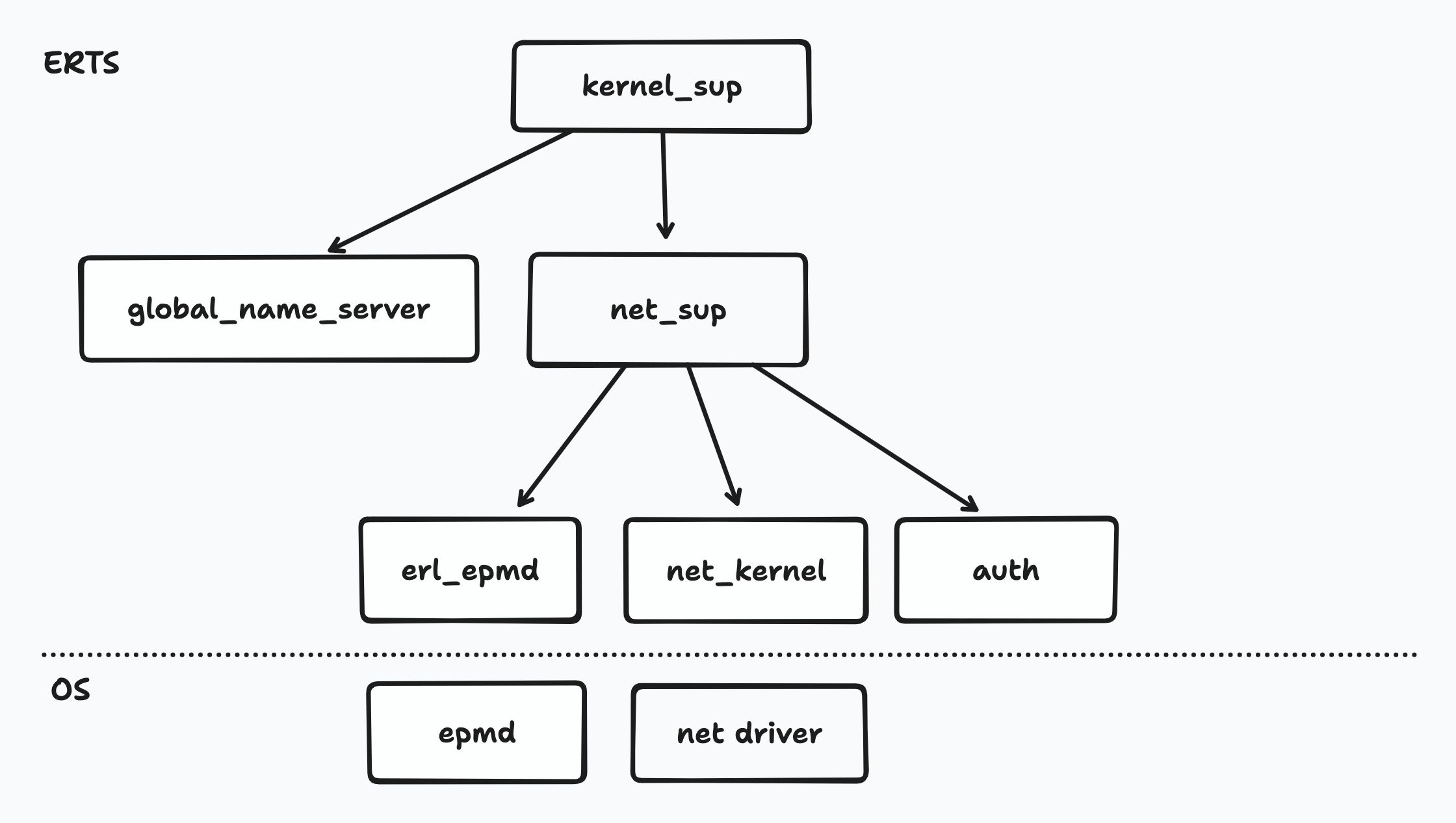
You can see that we have a corresponding erl_epmd server that interacts with the epmd daemon. There's also something I called ned driver - this is a Port driver that exposes a consistent API to the VM to deal with Operating System Syscalls and network socket handling. The auth server manages the cookies (more on that later) and the global_name_server is the name of the parent :global process.
If you really want to go down the rabbit hole even more, look into implementing an Alternative Carrier for Erlang distribution. The official docs present a great example using Unix Domain Sockets! The underlying mechanism by which the OS is handling IO will influence how our Elixir program runs, specially in a distributed setup where it needs to accept many socket connections. See this thread in the Erlang Forums for a discussion of kqueue and epoll at the OS level
Net Kernel
As the name implies, this is the Erlang Networking Kernel and is responsible for monitoring the network among other things. We can inspect the state of the server on one of our nodes:
iex(app2@raz.local)2> :sys.get_state(:net_kernel)
{:state, :"app2@raz.local", :longnames,
{:tick, #PID<0.62.0>, 60000, 4}, 7000, :sys_dist,
%{#PID<0.115.0> => :"app@raz.local"},
%{#Port<0.8> => :"app@raz.local"}, %{},
[
{:listen, #Port<0.2>, #PID<0.61.0>,
{:net_address, {{0, 0, 0, 0}, 50827}, 'raz', :tcp, :inet},
:inet_tcp_dist}
], [], 0, %{}, :net_sup, %{}}
What I'm interested in here is the PID and the Port parts. The PID is the identifier for the connecting handler process and the Port is the TCP socket that the two nodes use to both send heartbeats (ticks) and communicate. We can use a very simple tracer to listen in on the communication between the two nodes. It's helpful to explore this because it will give you the deep understanding you might need if you ever have to debug a cluster. I'm using pid(0,115,0) to pass the #PID<0.115.0> :
iex(app2@raz.local)3> :erlang.trace(pid(0,115,0), true, [:all])
1
iex(app2@raz.local)4> flush()
{:trace_ts, #PID<0.115.0>, :in, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885638}}
{:trace_ts, #PID<0.115.0>, :receive, {#PID<0.60.0>, :tick}, 1,
{1697, 299779, 885673}}
{:trace_ts, #PID<0.115.0>, :out, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885701}}
{:trace_ts, #PID<0.115.0>, :in, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885708}}
{:trace_ts, #PID<0.115.0>, :out, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885730}}
{:trace_ts, #PID<0.115.0>, :in, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885860}}
{:trace_ts, #PID<0.115.0>, :receive, {:inet_reply, #Port<0.8>, :ok}, 1,
{1697, 299779, 885869}}
{:trace_ts, #PID<0.115.0>, :out, {:dist_util, :con_loop, 2}, 1,
{1697, 299779, 885875}}
:ok
Great, we can see the connection loop and the back and forth messages that maintain the mesh network. Another helpful command to debug straight from the console is :inet.i(), which lists the ports, modules and processes that maintain the network.
iex(app2@raz.local)5> :inet.i() Port Module Recv Sent Owner Local Address Foreign Address State Type 16 inet_tcp 0 0 <0.60.0> *:50827 *:* ACCEPTING STREAM 32 inet_tcp 6 19 <0.58.0> localhost:50828 localhost:epmd CONNECTED(O) STREAM 64 inet_tcp 1639 1418 <0.115.0> localhost:50827 localhost:50853 CONNECTED(O) STREAM
Global
The global process name registry is started along with the rest of the tree when we start the distribution. It plays a direct role in maintaining the network. As of OTP 25, it comes with a new feature enabled by default that aims to prevent overlapping partitions in the mesh network. Global subscribes to nodeup and nodedown messages and when it detects that a node disconnected, it broadcasts a message to the whole network to try and get all nodes to disconnecte from the dead node.
This may sound like a great feature, but in reality, in distributed systems it is impossible to distinguish latency from failure. A node might not respond in time to a heartbeat, be considered dead by the network and end up resurfacing after the network delays to cause havoc. Collective wisdom about global and distributing Erlang is that you should not use it. There is indeed a way to start the distribution manually without global. The network is still maintained by the net_kernel server and if you need to register process names you can rely on the wonderful new pg module. In a future post I will explore a distribution setup without global.
Auth
Lastly, there's the auth server. The official docs mention that it is deprecated, although I can confirm that the server is started in the supervision tree (as indicated above). I won't spend too much time on this except to say that auth manages the cookie handshake that nodes exchange when connecting to each other.
MD5 hashes of the cookies are compared over the network and if they match, the nodes proceed with the connection. They are not meant to be secure but rather more of a way to group servers together.
You may be wondering why you're able to just connect local nodes together without specifying a cookie. That's because the first time you start a distributed node, the runtime creates a file called .erlang.cookie in your home directory, if you don't specify a cookie, ERTS will use that one for all the nodes.
Ok, now what?
To close off, I will leave you with a few ideas on how you can play with a small cluster of nodes.
Simple Message Passing
This is the canonical example adapted to Elixir from Learn You some Erlang by Fred Hebert. Given two connected nodes we will send a message from node app to node app2. We need a process to send the message to, and since we're in the iex console, we'll register the iex console's Process PID to a handy name in both nodes to make this easier:
iex(app@raz.local)1> Process.register(self(), :node)
And the same on the other node's console:
iex(app2@raz.local)1> Process.register(self(), :node)
We're calling both :node, but they will each point to their own local iex PID. If you inspect the self() PID you'll notice that it has the same value on both nodes, but you know each of them are local pids because they both start with 0 : <0.xx.xx>
Now let's send a message:
iex(app@raz.local)2> Process.send({:node, :"app2@raz.local"}, {:hello, :from, self()}, [])
And we can flush() the messages in the current process in the other console:
iex(app2@raz.local)2> flush()
{:hello, :from, #PID<12056.113.0>}
:ok
Note that the PID on the other side does not start with 0 anymore, but some other arbitrary number to denote a remote node.
Distributed key value
The second example is from Johanna Larsson's Keynote at CodeBeam Lite Mexico 2023: building a distributed key, value store using the ex_hash_ring library from Discord.
Phoenix PubSub
The third example is something I used in my own exploration of Distributed Elixir: Phoenix.PubSub. The easiest way to get up and running is to start an new mix project (you don't need Phoenix! but make sure to add supervision tree by adding --sup):
mix new --sup pubsub_node
You'll need to add the dependency in your `mix.exs` and also start the PubSub server:
# in mix.exs
defp deps do
[
{:phoenix_pubsub, "~> 2.1"}
]
end
# in lib/pubsub_node/application.ex
children = [
{Phoenix.PubSub, name: :my_pubsub}
]
Now back to our nodes, run each with --name to start a distribution by default. Don't forget to run mix because otherwise we won't run the project, but a completely separate iex console:
$ iex --name app -S mix iex> Node.connect(:"app2@raz.local")
Now we can subscribe to the same topic from both nodes:
iex> Phoenix.PubSub.subscribe(:my_pubsub, "user:123")
And broadcast a message:
iex(app@raz.local)3> Phoenix.PubSub.broadcast(:my_pubsub, "user:123", {:user_update, %{id: 123, name: "Shane"}})
:ok
And then on the other side:
iex(app2@raz.local)2> flush()
{:user_update, %{id: 123, name: "Shane"}}
:ok
And there you have it, seamlessly broadcasting and subscribing to topics across a distributed cluster of nodes! I strongly encourage you to check out the source code of the Phoenix PubSub library - it's both easy to understand and will also give you a glimpse into how something like pg can be used to work with distributed process groups.
To be continued...
We only scratched the surface here and left out a lot of important concepts. In future posts we will explore topics such as:
- Orchestration and service discovery
- Tuning the default distribution
- Running large clusters
Member discussion